本文探讨了开源许可证在非代码资产(如文档、数据和模型权重)中的应用,尤其是在大规模语言模型和生成式AI背景下。传统软件许可证(如MIT、Apache)已无法满足这些资产的需求。文章分析了Creative Commons、开放数据库许可证和OpenRAIL等不同类型的许可证,强调选择合适许可证的重要性,以确保合法合规并促进资源的有效使用。
本文提出了一种名为注意残差(AttnRes)的方法,以改善大规模语言模型中的残差连接。传统方法使用固定权重累积层输出,导致隐藏状态随深度增长而失控。AttnRes通过软最大注意力聚合前层输出,使每层能够根据输入选择性聚合先前表示。为降低大规模模型训练的内存和通信开销,提出了块级注意残差(Block AttnRes),通过分块处理层来减少内存占用,同时保持性能提升。实验表明,AttnRes在不同模型规模中有效改善了输出均匀性和下游任务表现。
英特尔Arc Pro B系列GPU具备强大的AI能力,支持本地运行大规模语言模型(LLM),优化多GPU性能和数据传输。vLLM软件栈提升推理效率,适合专业人士使用。
这篇博客推荐书籍《大规模语言模型:从理论到实践》,认为其为中文领域较为系统的预训练模型学习资料,内容更新及时,适合跳读,帮助读者发现知识盲点。
本文探讨了在Meta进行大规模语言模型推理的挑战与解决方案,强调了模型与硬件适配、推理速度优化、内存与缓存管理等关键步骤。分布式推理和高效资源管理是提升性能的关键,同时需关注生产环境的复杂性与可扩展性。成功的LLM服务需综合考虑模型、硬件与系统的优化。
本研究提出了无学习范式UniErase,有效解决了大规模语言模型中的知识冲突和过时信息问题,取得了最新的SOTA表现。
本研究探讨了大规模语言模型(LLM)与小型模型(SM)协作的潜力,以应对LLM对数据和计算资源的高需求。提出了一种新方法,加速LLM在特定领域的适应,并强调基于真实数据集的多目标基准研究的重要性。
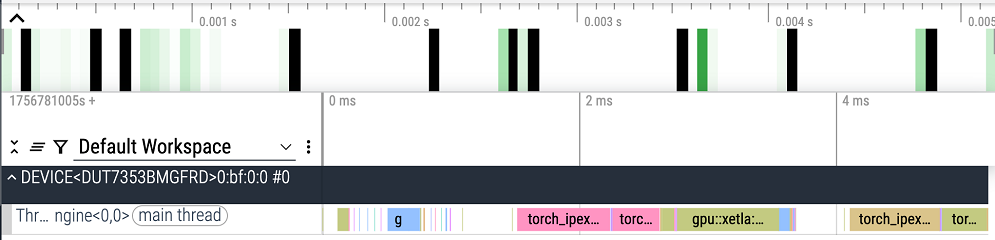
本研究分析了大规模语言模型在CPU-GPU耦合架构下的推理特征,结果显示紧耦合系统在大批量处理时性能优于松耦合系统,但在小批量时受限于CPU。内核融合技术能够缓解低批量的延迟瓶颈。
本研究提出了SymRTLO框架,结合大规模语言模型与符号推理技术,旨在提升RTL代码优化效果。该方法通过检索增强生成系统和抽象语法树模板进行代码重写,显著改善功耗、性能和面积,解决了传统方法在复杂设计约束下的挑战。
本研究提出了Prism框架,利用蒙特卡洛树搜索技术进行动态基准测试,以评估大规模语言模型(LLM)的代码生成能力,并揭示其性能限制。
本研究提出了AutoPDL,一种自动化提示优化方法,旨在解决大规模语言模型(LLM)提示配置的人工调优问题。该方法将提示优化视为结构化的AutoML问题,能够高效导航组合空间,显著提升多种任务和模型的准确性,具有广泛应用潜力。
本研究提出了一种扩散驱动提示调优(DDPT)方法,旨在解决大规模语言模型在代码生成中对提示质量的依赖问题,从而显著提升提示优化效果。
本研究提出了CO-Bench基准套件,包含36个实际组合优化问题,旨在评估大规模语言模型(LLM)在组合优化中的应用。通过与传统算法的对比,揭示了现行方法的优缺点,并指出了未来的研究方向。
本研究探讨了大规模语言模型在幽默理解方面的不足,通过将幽默理解分解为三个部分并进行改进,达到了82.4%的字幕排名准确率,超越了67%的基准,接近人类专家水平。这表明与特定群体对齐能有效提升模型的创意判断能力。
本研究提出了雅可比稀疏自编码器(JSAEs),解决了传统稀疏自编码器仅关注激活稀疏性的问题。JSAEs实现了输入、输出激活及连接的雅可比矩阵的稀疏性,在保持大规模语言模型(LLM)性能的同时,提升了计算稀疏性,强调了计算图稀疏性在LLM训练中的重要性。
本研究解决了Muon优化器在大规模语言模型训练中的可扩展性问题。新技术使Muon无需超参数调优即可实现约2倍的计算效率提升,且在参数较少时表现更佳。
本研究提出了一种名为LUNAR的新方法,用于大规模语言模型(LLM)的遗忘。该方法通过重定向未学习数据的表示,显著提升了模型的可控性和遗忘效果,测试结果显示性能提升高达11.7倍,且具有良好的适应性和鲁棒性。
本研究首次分析了大规模语言模型(LLMs)在83个软件工程基准中的数据泄露问题。尽管总体泄露率较低,但部分基准的泄露率显著较高,影响评估结果。为此,提出了新的基准LessLeak-Bench,以提高未来研究的可靠性。
本研究探讨了大规模语言模型(LLMs)与知识图谱(KGs)之间的元语言不一致性问题,提出了一个检测基准,以评估二者的事实性和元语言不一致性,为知识图谱构建提供新工具。初步验证已在Github发布。
本研究探讨了大规模语言模型(LLMs)在儿童抑郁症诊断中的应用,发现其在提取抑郁症状方面的效率比传统方法高60%。LLMs在识别罕见症状方面表现优异,显示出其在减少诊断错误和补充传统筛查中的重要价值。
完成下面两步后,将自动完成登录并继续当前操作。