
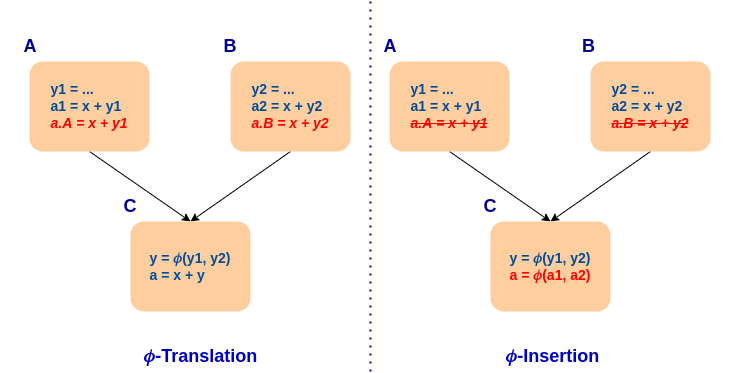
GSoC 2024:重振 NewGVN
The LLVM Project Blog
·

Unigine 2.19 推出 OpenXR 支持和多线程渲染器
实时互动网
·
让推理有意义:衡量和提升思考推理的可靠性
BriefGPT - AI 论文速递
·
知识图谱中半归纳链接预测的基准测试
BriefGPT - AI 论文速递
·
利用大型预训练模型与适配器混合进行领域泛化
BriefGPT - AI 论文速递
·
