本文讨论了PostgreSQL中的两个重要检查点参数:checkpoint_timeout和checkpoint_completion_target。检查点是确保脏页写入磁盘的时刻,影响崩溃恢复时间。建议将checkpoint_timeout设置为至少15分钟,以减少写放大和I/O负担,同时将checkpoint_completion_target设置为0.9,以平滑I/O负载。合理配置可提高系统性能和稳定性。
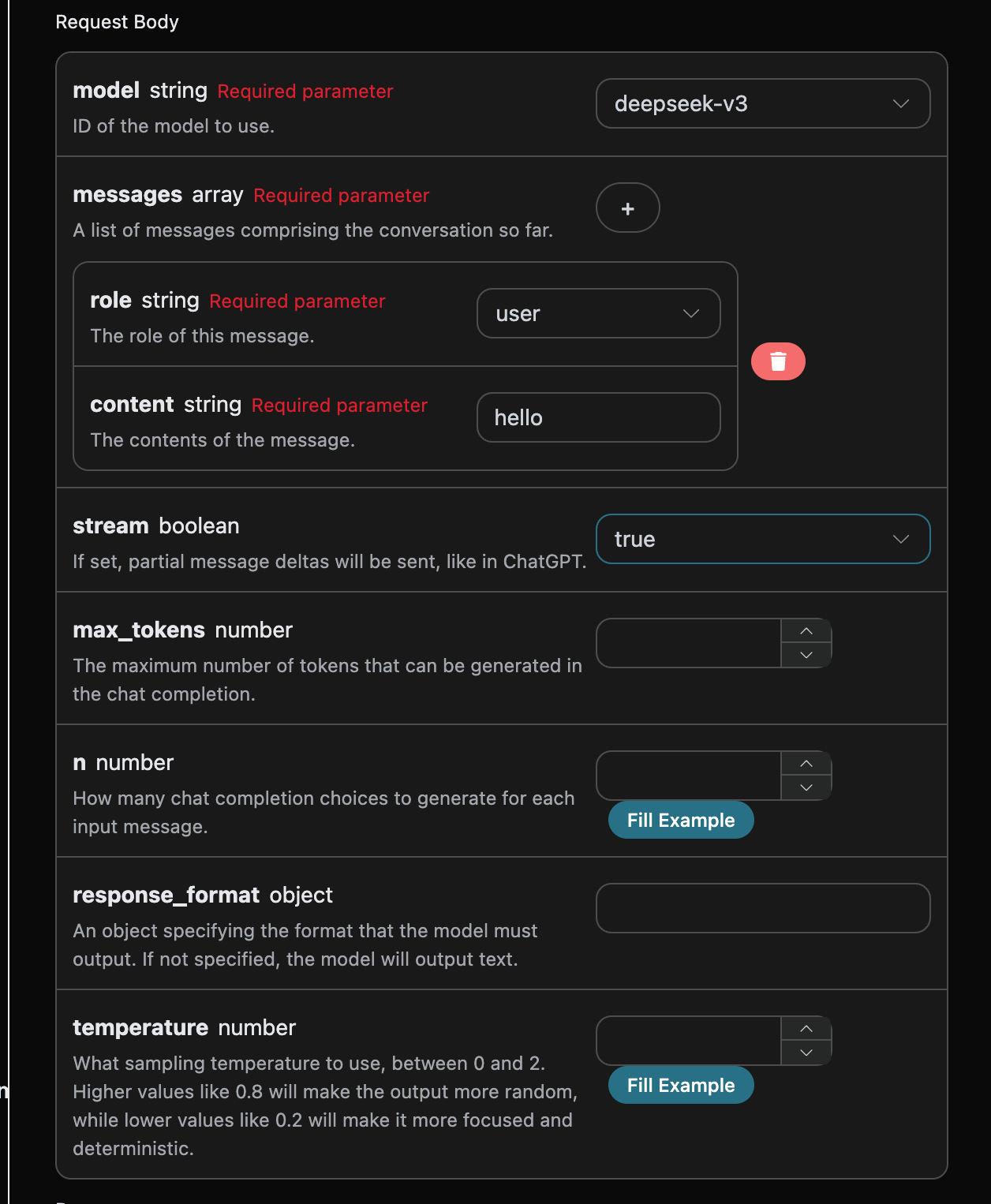
本文介绍了如何申请和使用 DeepSeek Chat Completion API。用户需注册并获取凭证,填写相关参数后即可调用 API。提供了 Python、JavaScript 等语言的示例代码,支持多轮对话和流式响应功能,并列出了常见错误及处理方法。
ESLint version 10 has removed the legacy eslintrc configuration system, finalizing a long transition to flat config. The update enhances developer experience, especially for plugin authors and...
Google Gemini 是一款强大的 AI 对话系统,用户可通过输入提示词快速生成自然回复。本文介绍了 Gemini Chat Completion API 的申请流程、基本使用方法及多轮对话功能,帮助用户轻松实现对话功能。
自2020年以来,OpenAI的文字生成API从单次文字生成演变为支持多轮对话的架构。/v1/completions用于单次生成,而/v1/chat/completions则支持多轮对话、角色理解和多模态输入。随着GPT-4o和GPT-5的推出,Chat API成为主流,未来将统一所有生成和工具应用。
本研究提出了两种新评估指标LCP和ROUGE-LCP,以缩小代码补全评估与用户感知之间的差距。同时,提出了一种基于结构和语义重排的代码图数据处理方法,显著提高了用户感知一致性和模型性能。
本研究提出了一种新方法,解决联合学习中的数据质量问题,如噪声标签和缺失类别。通过自适应噪声清理和基于GAN的合成数据生成,实验表明该方法在MNIST和Fashion-MNIST数据集上显著提升了联邦模型性能,为边缘设备提供了稳健的隐私合规解决方案。
本研究提出了一种新方法ReCDAP,旨在解决知识图谱中关系分布不均的问题。通过条件整合正负三元组信息,ReCDAP克服了传统方法的局限,实验证明其在多个数据集上表现优异,具有较高的应用潜力。
本研究通过结合预训练的欧几里得模型与超曲线交互项,解决了知识图谱补全中的几何表达不足问题,从而提高了链接预测的准确性和数据分布特性的捕捉能力。
本研究提出了一种新方法GLTW,结合改进的图变换器与大型语言模型,提升知识图谱完成的准确性。实验结果显示,GLTW在多个数据集上超越了现有的基线模型。
本研究提出了一种将材料属性预测建模为张量补全的新方法,显著提高了设计组合的探索效率。实验结果表明,该方法在材料属性预测中的错误率降低了10-20%,训练速度与传统机器学习模型相当,具有显著的改进潜力。
本研究提出了一种基于变换器的多模态知识图谱补全方法,解决了传统方法在处理真实世界图谱时的效率和规模问题。通过结合知识图谱嵌入模型与预训练的视觉语言模型生成的跨模态上下文,显著缩小了模型规模,并在多个大规模数据集上保持了竞争性能。
本研究提出了一种基于扩散的层次负采样(DHNS)方案,旨在解决多模态知识图谱中的缺失知识问题。实验结果表明,该方法结合多模态语义和动态训练策略,在多个基准数据集上显著优于现有模型,提升了训练效果。
本研究提出了一种基于大型语言模型(LLMs)构建知识图谱的方法,以优化高等教育中的个性化学习路径推荐。研究表明,该方法有效整合不同学科课程,提升学习体验,并获得专家认可。
本研究提出了一种新型主动采样算法(ATS),用于恢复图分析中的缺失节点属性。该算法通过评估节点信息的代表性和不确定性,展现出优越性,具有实际应用潜力。
本研究提出KG-TRICK框架,旨在解决多语言知识图谱在非英语语言下的信息不完整问题。通过统一关系和文本信息补全,显著提高了知识图谱的完整性,并推出WikiKGE10++数据集作为基准。
本研究提出KG-CF框架,旨在解决知识图谱补全中的上下文过滤问题。通过利用大型语言模型的推理能力,显著提升了知识图谱补全的准确性和实用性。
本研究提出ExecRepoBench框架和Repo-Instruct指令语料库,旨在解决现有代码补全评估基准的不足,从而提升开源大型语言模型在复杂编码场景中的表现。
本研究提出了一种名为FtG的新方法,通过“过滤-再生成”范式提升大型语言模型在知识图谱补全中的性能。该方法将任务转化为多选题格式,结合结构与文本信息,有效减轻幻觉问题,实验结果显示性能显著提高。
本研究探讨跨视角补全学习,填补自监督对应学习的分析空白。研究发现,跨注意力图能更有效地捕捉对应关系,并在零-shot 匹配和多帧深度估计中表现优异,显示出良好的应用潜力。
完成下面两步后,将自动完成登录并继续当前操作。