
在NVIDIA H100 Tensor Core GPU上部署量化的大型语言模型
💡
原文英文,约1700词,阅读约需6分钟。
📝
内容提要
量化是一种使机器学习模型更小更快的技术。将量化应用于Llama2-70B-Chat模型可以每秒生成2.2倍的标记。量化减少了内存占用并实现了更快的推理。可以应用于模型参数、键值缓存和激活。量化产生了更小的模型,减少了GPU内存使用量,并增加了最大批处理大小。NVIDIA A100和H100 Tensor Core GPU支持快速低精度操作。介绍了INT8和FP8量化设置,FP8通常产生更准确的模型。量化Llama2-70B-Chat模型使模型减小了50%,输出标记生成速度提高了30%,并且与原始模型具有相同的质量。量化还提高了模型吞吐量和并发性。H100 GPU的性能优于A100 GPU。量化后保持了模型质量。
🎯
关键要点
- 量化是一种使机器学习模型更小更快的技术。
- 对Llama2-70B-Chat模型进行量化后,每秒生成的标记数量提高了2.2倍。
- 量化减少了内存占用并实现了更快的推理。
- 可以对模型参数、键值缓存和激活进行量化。
- 量化使模型减小了50%,并提高了输出标记生成速度30%。
- 量化后模型的吞吐量和并发性得到了提升。
- H100 GPU的性能优于A100 GPU。
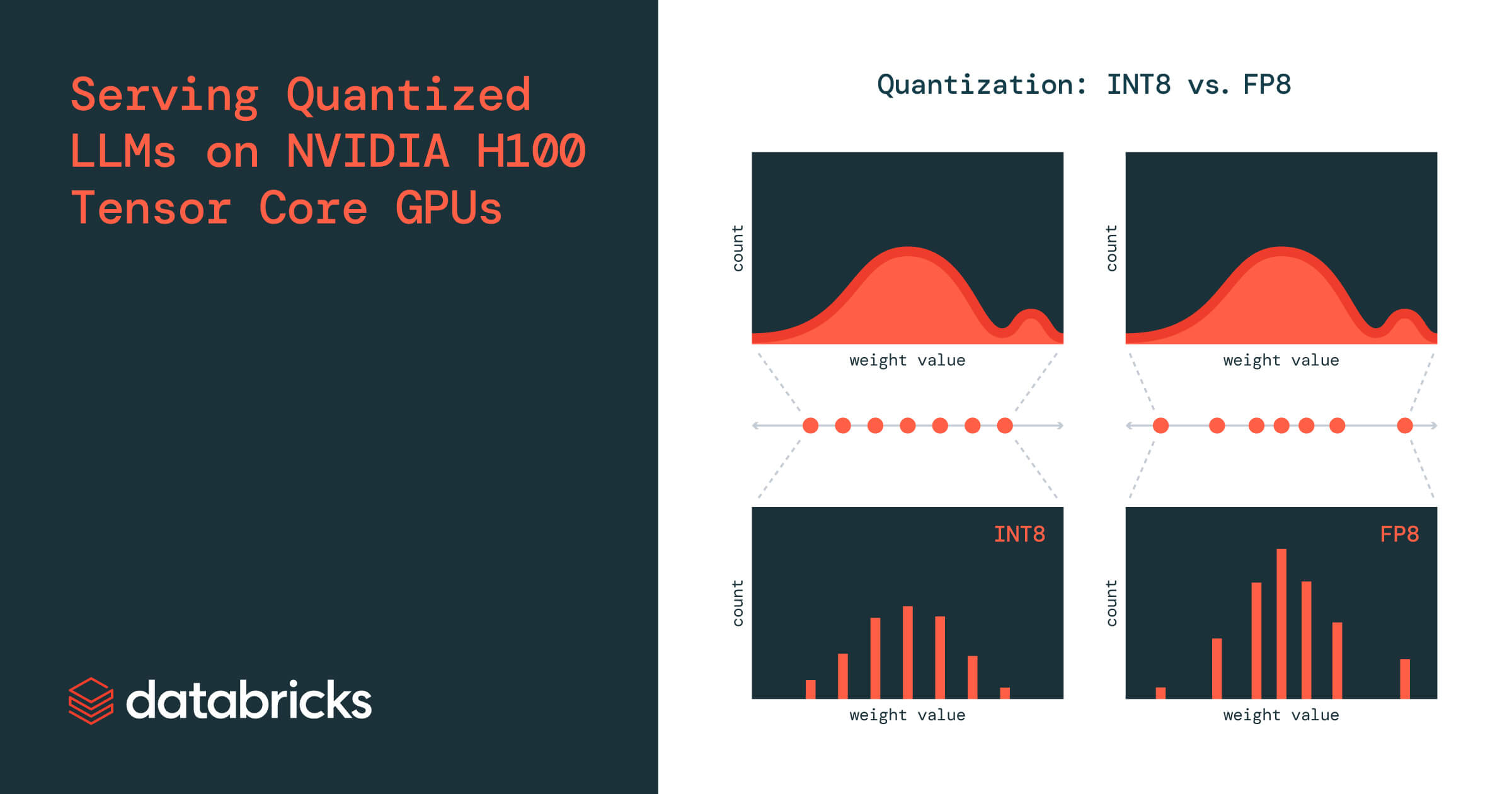
- INT8和FP8是两种不同的量化设置,FP8通常产生更准确的模型。
- 量化后保持了模型质量,且与原始模型质量相同。
- 量化可以提高最大批处理大小,减少GPU内存使用量。
- 在低批量设置下,量化模型的TPOT和吞吐量提高了约30%。
- 使用FP8量化,整体模型吞吐量提高了2.2倍。
- 量化模型在Gauntlet评估中与基线模型的准确性差异不显著。
➡️
