
通过微调嵌入模型提升检索和检索增强生成(RAG)
内容提要
微调嵌入模型能显著提高向量搜索和检索增强生成(RAG)的准确性,尤其在金融文档和知识库中表现优异。研究表明,微调模型在多个数据集上提升了检索准确率,且无需手动标注数据。
关键要点
-
微调嵌入模型能显著提高向量搜索和检索增强生成(RAG)的准确性。
-
在金融文档、知识库和内部代码文档中,微调可以提供更相关的搜索结果和更好的下游LLM响应。
-
研究表明,微调模型在多个数据集上提升了检索准确率,且无需手动标注数据。
-
微调嵌入模型可以提高检索准确性,增强RAG性能,并改善成本和延迟。
-
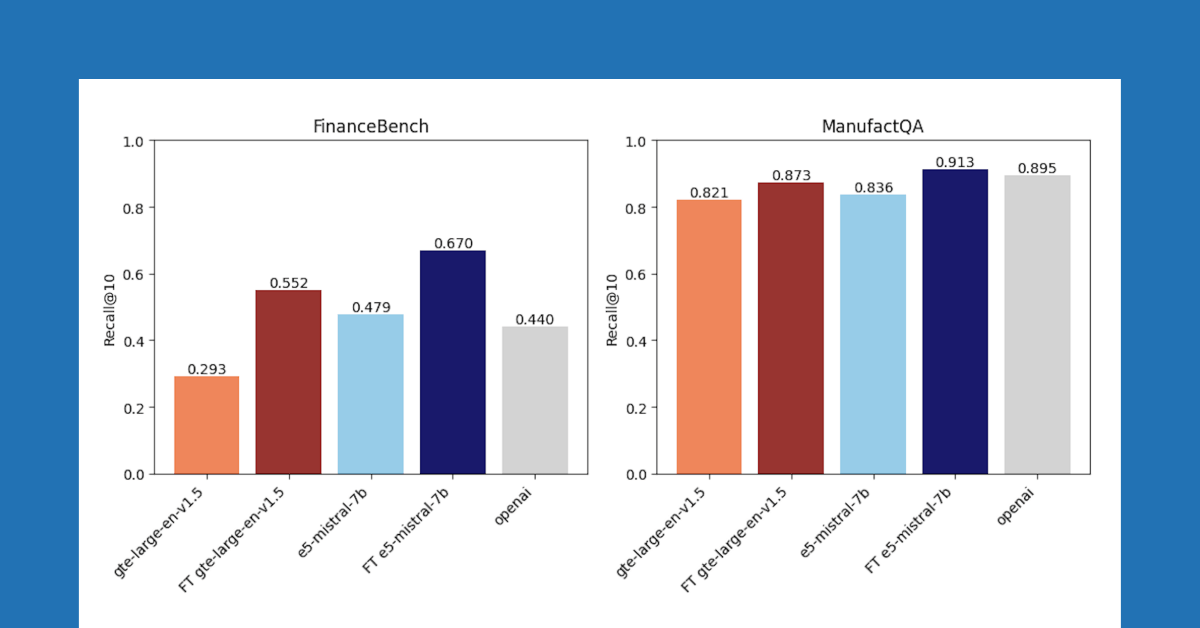
微调后的嵌入模型在多个数据集上表现优异,常常显著超越基线模型。
-
微调模型在FinanceBench和ManufactQA上超越了重排序,而在Databricks DocsQA上效果较弱。
-
重排序通常会增加每次查询的延迟和成本,但在某些情况下可能比重新嵌入数据更具成本效益。
-
在检索已经强大的领域中,微调的效果有限,最佳效果出现在检索是瓶颈的情况下。
延伸解读
微调模型的优势
微调嵌入模型能够显著提升检索准确性,尤其在特定领域如金融文档和知识库中表现突出。这种方法不仅提高了搜索结果的相关性,还能改善后续生成模型的响应质量,适合需要高精度检索的企业应用。
微调与重排序的比较
微调模型在某些数据集上超越了重排序方法,尤其是在FinanceBench和ManufactQA中表现优异。然而,在Databricks DocsQA中,重排序的效果更佳,说明不同数据集对方法的适应性差异显著,选择时需考虑具体场景。
成本与延迟的考量
微调后的嵌入模型通常在成本和延迟上更具优势,尤其是当检索性能成为瓶颈时。然而,重排序虽然可能增加查询延迟,但在某些情况下可能更具成本效益,因此在选择时需权衡各自的优缺点。
延伸问答
微调嵌入模型如何提高检索准确性?
微调嵌入模型通过对特定领域数据的优化,能够提升向量搜索的准确性,从而提供更相关的搜索结果。
在什么情况下微调嵌入模型效果最佳?
微调效果最佳的情况是当检索过程成为瓶颈时,特别是在检索准确性较低的领域。
微调嵌入模型是否需要手动标注数据?
不需要,微调模型可以利用现有数据进行优化,而无需手动标注。
微调嵌入模型对RAG性能有何影响?
微调嵌入模型可以改善RAG性能,减少生成内容中的幻觉现象,提供更可靠的生成响应。
微调模型与重排序的比较如何?
在某些数据集上,微调模型的表现优于重排序,而在其他情况下,重排序的效果可能更好,具体取决于数据集和任务。
微调嵌入模型的成本和延迟如何?
微调后的模型通常可以在成本和延迟上优于更大、更昂贵的模型,尤其是在特定任务中。
