

💡
原文中文,约1500字,阅读约需4分钟。
📝
内容提要
尽管多模态大型语言模型(MLLM)在英语上取得进展,但全球语言和文化的代表性仍不足。卡内基梅隆大学推出的PANGEA模型,使用包含39种语言的600万个样本的数据集PANGEAINS进行训练。评估结果显示,PANGEA在多语言任务上优于现有模型,并在多元文化理解方面表现突出。该模型的开源有望提升跨语言和文化的公平性与可访问性。
🎯
关键要点
- 多模态大型语言模型(MLLM)在英语上取得进展,但全球语言和文化代表性不足。
- 卡内基梅隆大学推出的PANGEA模型,使用包含39种语言的600万个样本的数据集PANGEAINS进行训练。
- PANGEA在多语言任务上优于现有模型,并在多元文化理解方面表现突出。
- PANGEAINS数据集结合高质量的英语教学、机器翻译教学和文化相关的多模态任务。
- PANGEABENCH评估套件涵盖14个数据集和47种语言,深入评估PANGEA的能力。
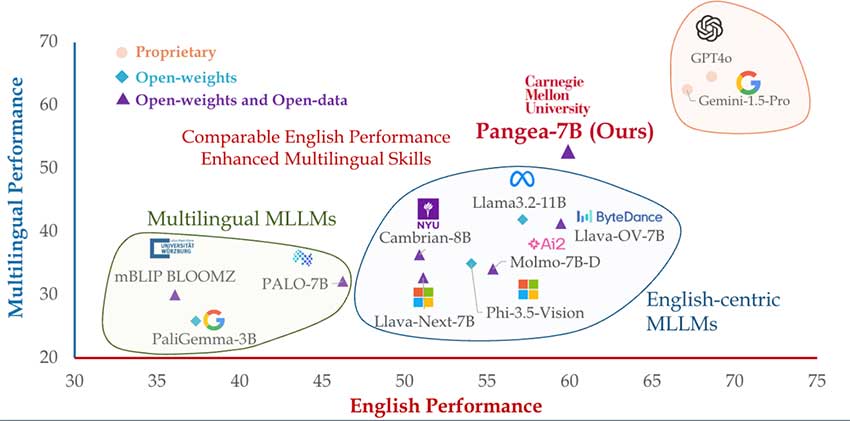
- PANGEA-7B模型在英语任务上平均提升7.3分,在多语言任务上平均提升10.8分。
- PANGEA在多元文化理解方面表现出色,跨语言能力均衡。
- PANGEA在多个领域的表现与Gemini-1.5-Pro和GPT4o等专有模型相当甚至更好。
- PANGEA的开源有望促进跨语言和文化的公平性与可访问性。
- 未来需要改进多模式聊天和复杂推理任务的性能。
➡️
