

💡
原文中文,约5700字,阅读约需14分钟。
📝
内容提要
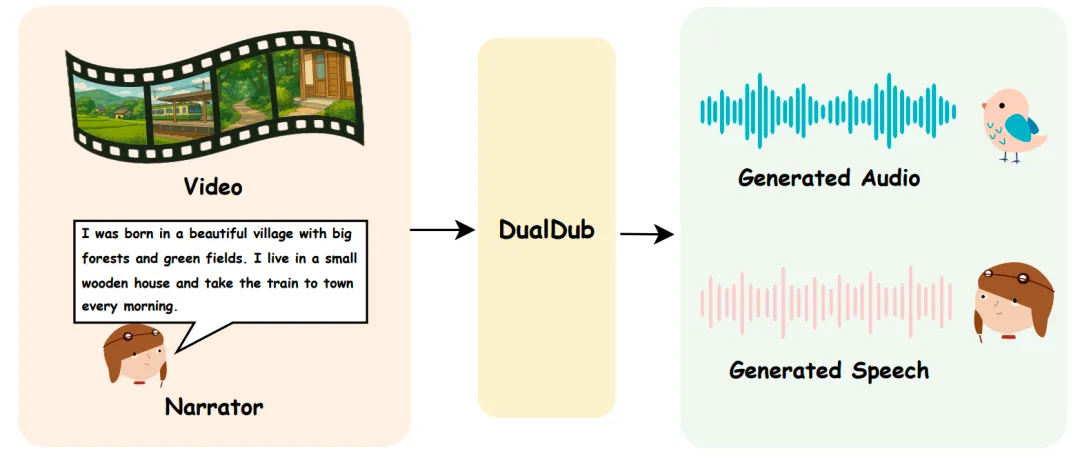
西工大音频语音与语言处理研究组提出的DualDub模型,旨在同时生成视频的背景音频和语音,解决了现有视频到音频模型忽视语音的问题。该模型通过多模态编码器和对齐模块,实现音频与语音的同步生成,并引入DualBench基准测试集,实验结果显示其在生成质量和时间同步性方面表现优异。
🎯
关键要点
- 西工大音频语音与语言处理研究组提出DualDub模型,旨在同时生成视频的背景音频和语音。
- DualDub模型解决了现有视频到音频模型忽视语音的问题。
- 该模型通过多模态编码器和对齐模块,实现音频与语音的同步生成。
- 引入DualBench基准测试集,评估生成质量和时间同步性。
- DualDub包含三个主要组件:多模态编码器、多模态对齐器和多模态语言模型。
- 多模态对齐模块结合因果注意力与非因果注意力机制,提升生成内容的时间同步性和声学和谐性。
- 提出课程学习策略,逐步构建模型的多模态能力以应对数据稀缺问题。
- 实验结果表明,DualDub在生成高质量、时间同步的音轨方面表现优异。
- 评估指标分为生成质量、音视频对齐度和音频-语音和谐度。
- DualDub在Video-to-Audio和Video-to-SoundTrack任务上均表现良好,展示了其强大的语音生成能力。
➡️
