

针对Anthropic和OpenAI模型的提示缓存:构建成本高效的AI系统
💡
原文英文,约1900词,阅读约需7分钟。
📝
内容提要
大型语言模型(LLMs)在现代AI应用中至关重要,但重复发送长提示会迅速增加成本。提示缓存技术的出现允许重用相同的提示部分,从而显著降低延迟和费用,开发者可将成本降低70-90%。这种优化在高流量应用中尤为有效。
🎯
关键要点
- 大型语言模型(LLMs)是现代AI应用的基础组成部分。
- 重复发送长提示会迅速增加成本,尤其是在高流量应用中。
- 提示缓存技术允许重用相同的提示部分,从而显著降低延迟和费用。
- 提示缓存通过存储和重用相同的提示段来减少计算和费用。
- 提示缓存的优势包括显著降低成本、减少延迟和提高可扩展性。
- 提示缓存在许多AI应用中效果显著,如ChatGPT、Cursor和知识库助手等。
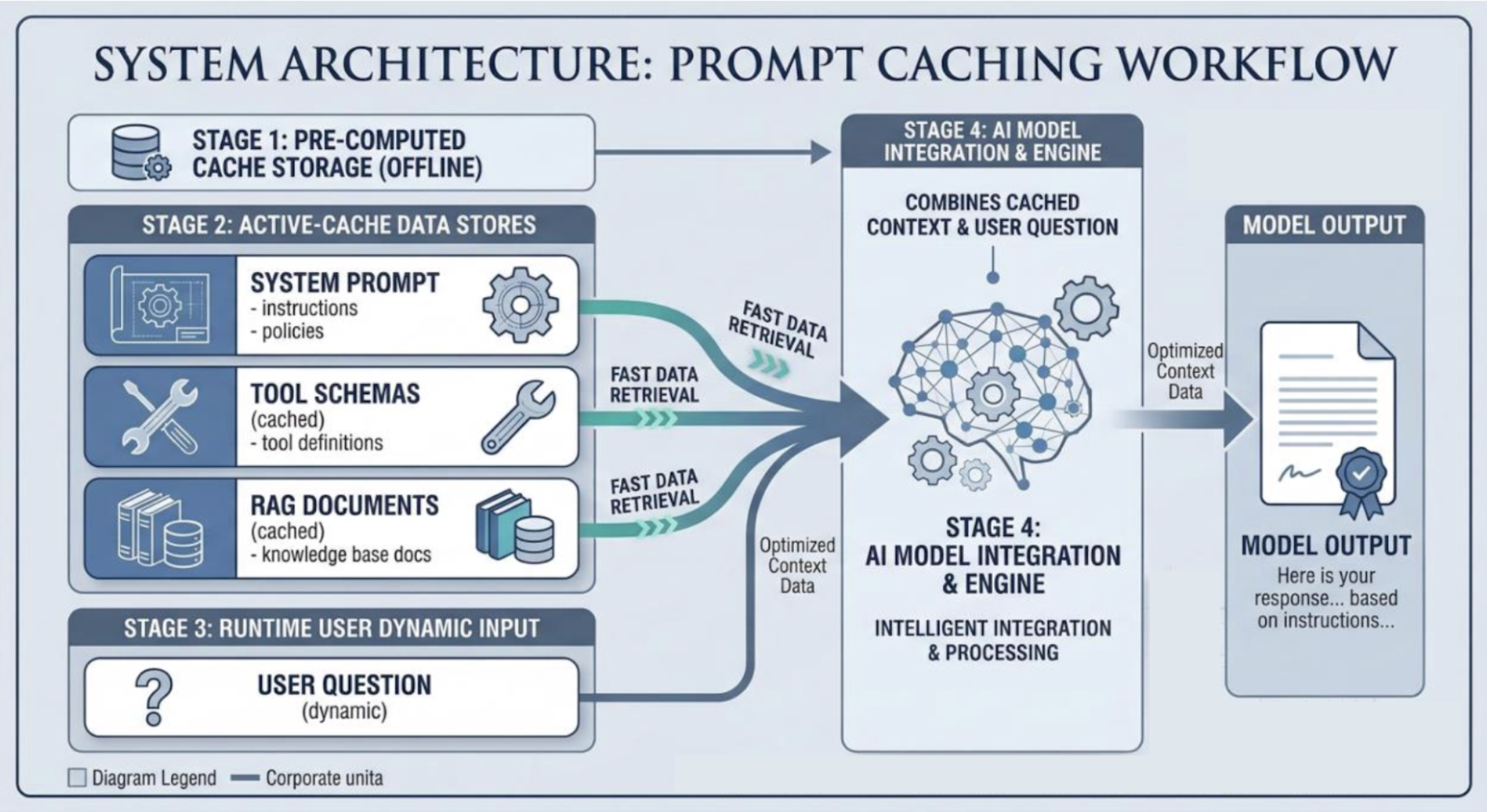
- 生产AI系统的常见架构将提示分为静态和动态部分,以便缓存。
- 使用提示缓存可以将令牌成本降低70-90%。
- 开发者可以通过DigitalOcean实现提示缓存,支持Anthropic和OpenAI模型。
- 提示缓存已成为降低LLM基础设施成本的强大技术。
➡️
