
针对Anthropic和OpenAI模型的提示缓存:构建成本高效的AI系统
内容提要
大型语言模型(LLMs)在现代AI应用中至关重要,但重复发送长提示会迅速增加成本。提示缓存技术的出现允许重用相同的提示部分,从而显著降低延迟和费用,开发者可将成本降低70-90%。这种优化在高流量应用中尤为有效。
关键要点
-
大型语言模型(LLMs)是现代AI应用的基础组成部分。
-
重复发送长提示会迅速增加成本,尤其是在高流量应用中。
-
提示缓存技术允许重用相同的提示部分,从而显著降低延迟和费用。
-
提示缓存通过存储和重用相同的提示段来减少计算和费用。
-
提示缓存的优势包括显著降低成本、减少延迟和提高可扩展性。
-
提示缓存在许多AI应用中效果显著,如ChatGPT、Cursor和知识库助手等。
-
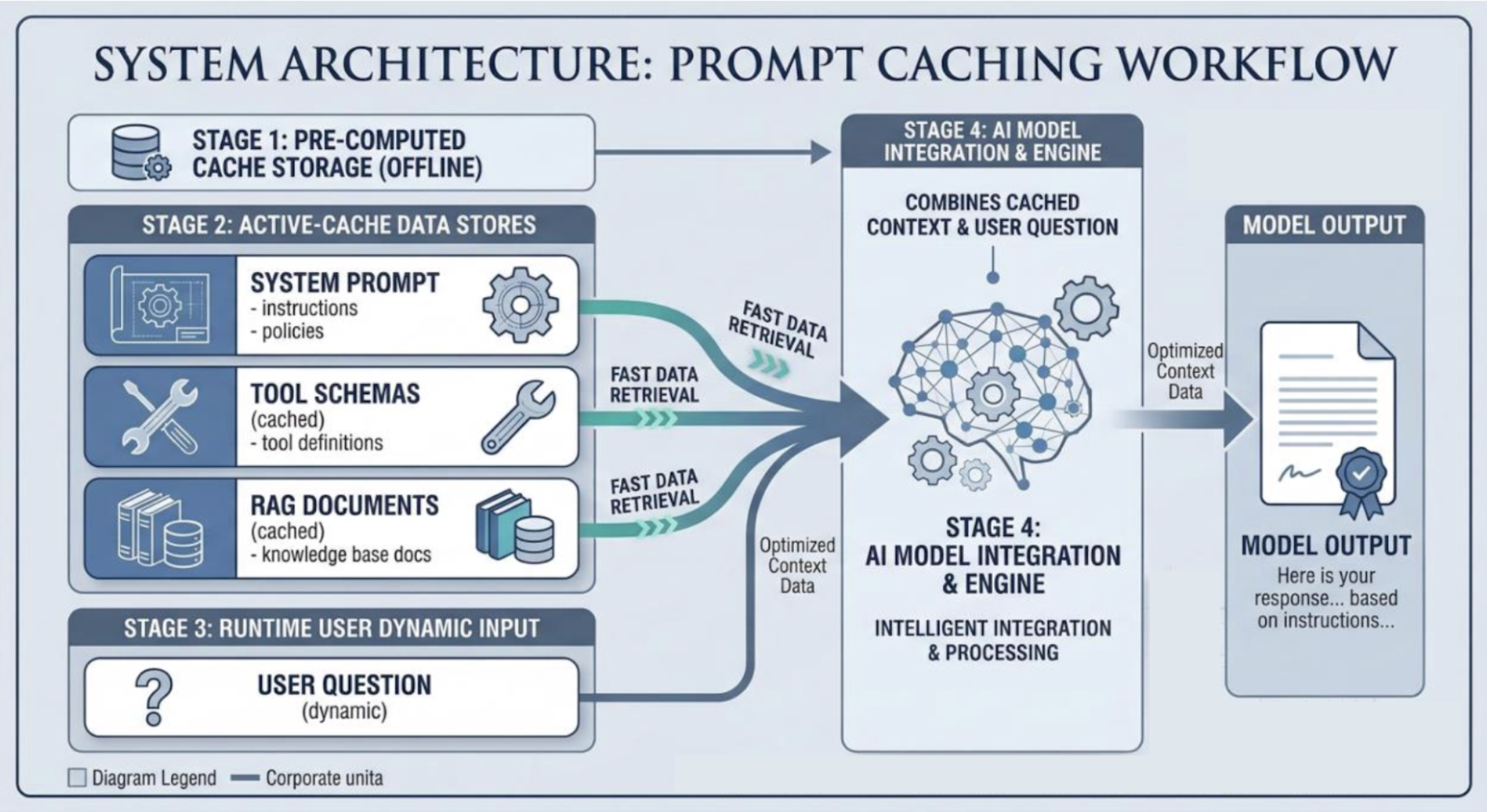
生产AI系统的常见架构将提示分为静态和动态部分,以便缓存。
-
使用提示缓存可以将令牌成本降低70-90%。
-
开发者可以通过DigitalOcean实现提示缓存,支持Anthropic和OpenAI模型。
-
提示缓存已成为降低LLM基础设施成本的强大技术。
延伸解读
提示缓存的实际应用场景
提示缓存技术在高流量的AI应用中尤为有效,尤其是像ChatGPT和知识库助手等场景。这些应用通常需要处理大量重复的提示内容,利用缓存可以显著降低计算成本和响应时间。开发者应关注这些应用的具体需求,以便更好地实施提示缓存策略。
成本节约的潜力
通过提示缓存,开发者可以将令牌成本降低70-90%。这种显著的成本节约对于大规模应用尤为重要,尤其是在处理数以万计的请求时。开发者在设计AI系统时,应考虑如何有效利用提示缓存来优化预算和资源配置。
提示缓存的技术实现
提示缓存的实现依赖于将静态和动态提示部分分开。开发者需要在系统架构中明确哪些部分可以缓存,以提高效率。了解不同模型提供商(如Anthropic和OpenAI)在缓存控制上的差异,有助于开发者选择合适的实现方式。
延伸问答
什么是提示缓存技术,它是如何工作的?
提示缓存技术是一种机制,通过存储和重用在多个请求中相同的提示部分,来减少计算和费用。它通过识别相同的前缀令牌来实现,避免每次请求都重新处理相同的内容。
使用提示缓存可以节省多少成本?
使用提示缓存可以将令牌成本降低70-90%,因为缓存的令牌收费远低于新处理的令牌。
提示缓存在哪些AI应用中效果显著?
提示缓存在ChatGPT、Cursor、知识库助手等高流量应用中效果显著,尤其是当大部分提示内容保持不变时。
提示缓存如何提高AI系统的可扩展性?
提示缓存通过防止在大量请求中重复计算相同的提示内容,从而显著提高AI系统的处理速度和可扩展性。
开发者如何在DigitalOcean上实现提示缓存?
开发者可以通过在请求中使用缓存控制参数来实现提示缓存,支持Anthropic和OpenAI模型的缓存功能。
提示缓存的主要优势是什么?
提示缓存的主要优势包括显著降低成本、减少延迟和提高系统的可扩展性,使得高流量应用更具经济性。
