
微软是最佳选择(但速度较慢),IBM超越大多数OpenAI产品:我测试50多种大型语言模型的发现
内容提要
大型语言模型(LLMs)如GPT-4和Claude 3被广泛应用。测试显示,微软的Phi-4在准确性上表现最佳,而IBM的Granite模型超越了许多OpenAI产品。选择应根据工作流程,推荐Phi-4用于本地执行,Gemini 1.5 Flash和Claude 3 Opus适合追求速度的用户。
关键要点
-
大型语言模型(LLMs)如GPT-4和Claude 3被广泛应用。
-
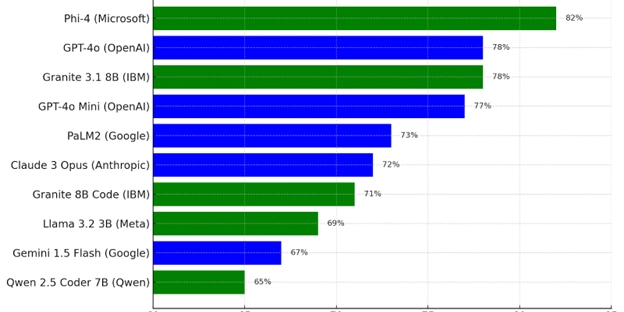
微软的Phi-4在准确性上表现最佳,IBM的Granite模型超越了许多OpenAI产品。
-
选择模型应根据工作流程,推荐Phi-4用于本地执行。
-
Gemini 1.5 Flash和Claude 3 Opus适合追求速度的用户。
-
测试使用真实开发任务,结果显示Phi-4的准确率为82%。
-
最快的云模型是Claude 3 Opus,首次响应时间为2.2秒。
-
本地模型中,Code Gemma 1.1 7B的首次响应时间为7秒,但准确率仅为5%。
-
LLMs的性能差异受系统提示、上下文窗口限制、训练数据和架构、硬件限制及参数数量等因素影响。
-
GPT-4o被评为整体最佳模型,尽管不是最快,但性能最为平衡。
-
推荐使用Phi-4以获得准确性和本地执行,Gemini 1.5 Flash和Claude 3 Opus适合速度需求。
延伸解读
选择模型的关键因素
在选择大型语言模型时,用户应考虑工作流程的具体需求。准确性与速度之间的权衡至关重要。例如,Phi-4在准确性上表现最佳,适合需要高精度的本地执行任务,而Gemini 1.5 Flash和Claude 3 Opus则更适合追求快速响应的用户。
性能差异的影响因素
大型语言模型的性能差异受到多种因素的影响,包括系统提示、上下文窗口限制、训练数据和模型架构等。了解这些因素有助于用户在实际应用中优化模型的使用,确保获得最佳的输出结果。
本地与云模型的比较
本地模型如Phi-4在准确性上表现突出,但响应时间较长,适合对准确性要求高的场景。而云模型如Claude 3 Opus则在速度上具有优势,适合需要快速反馈的应用。用户应根据具体需求选择合适的模型类型。
延伸问答
微软的Phi-4模型在测试中表现如何?
微软的Phi-4模型在准确性上表现最佳,准确率为82%。
IBM的Granite模型与OpenAI的产品相比如何?
IBM的Granite模型超越了许多OpenAI的热门产品,表现出色。
选择大型语言模型时应该考虑哪些因素?
选择模型应根据工作流程,考虑准确性和速度的权衡。
哪个模型适合追求速度的用户?
Gemini 1.5 Flash和Claude 3 Opus适合追求速度的用户。
在测试中,哪个模型的首次响应时间最快?
Claude 3 Opus的首次响应时间为2.2秒,是最快的云模型。
为什么不同的LLMs表现差异如此之大?
LLMs的性能差异受系统提示、上下文窗口限制、训练数据和架构、硬件限制及参数数量等因素影响。
