
Meta 推出 LlamaRL:基于 PyTorch 的可扩展强化学习 RL 框架,可实现高效的大规模 LLM 训练
内容提要
强化学习已成为微调大型语言模型(LLM)的重要方法。Meta推出的LlamaRL框架通过完全异步设计,优化了训练速度和内存使用,显著提升了405B参数模型的训练效率,解决了传统框架的瓶颈问题。
关键要点
-
强化学习是微调大型语言模型(LLM)的重要方法。
-
Meta推出的LlamaRL框架通过完全异步设计,优化了训练速度和内存使用。
-
强化学习能够根据结构化反馈调整输出,提升模型性能。
-
扩展LLM的强化学习面临巨大的资源需求和工程挑战。
-
传统框架存在效率低下和灵活性不足的问题。
-
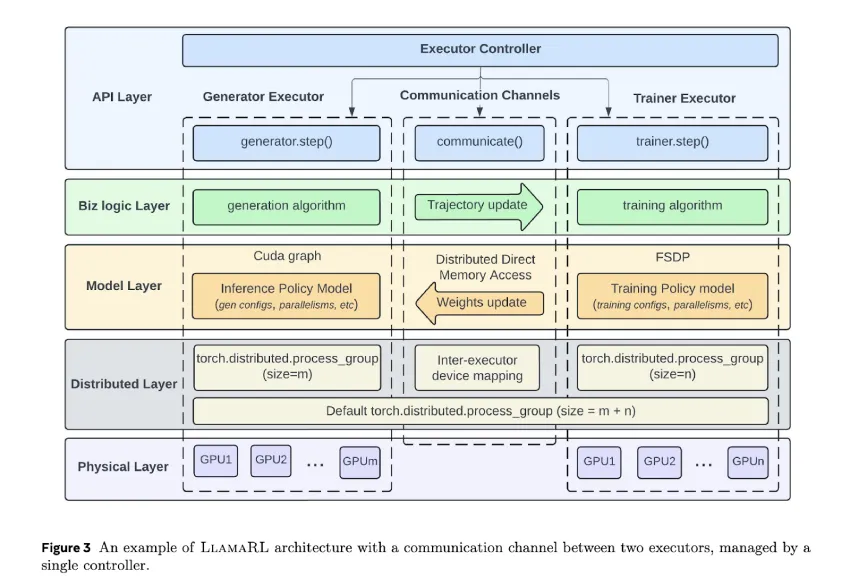
LlamaRL是一个基于PyTorch的分布式异步强化学习框架,支持模块化定制。
-
LlamaRL通过卸载生成过程和使用分布式直接内存访问(DDMA)提高内存效率。
-
LlamaRL在405B参数模型上将训练速度提高了10.7倍,显著提升了训练效率。
-
该框架解决了内存限制、通信延迟和GPU效率低下等问题,为LLM训练的未来发展提供了可扩展的解决方案。
延伸解读
强化学习的挑战与机遇
随着大型语言模型(LLM)的复杂性增加,强化学习在微调过程中的应用面临巨大的资源需求和工程挑战。尤其是在训练过程中,如何协调不同组件的工作成为关键。LlamaRL框架的推出,正是为了应对这些挑战,提供更高效的解决方案。
LlamaRL的技术优势
LlamaRL框架通过完全异步设计和模块化定制,显著提高了训练速度和内存使用效率。与传统框架相比,它能够更好地利用GPU资源,减少等待时间,从而加速大规模模型的训练。这种创新设计为未来的LLM训练提供了新的可能性。
性能基准的重要性
LlamaRL在405B参数模型上的训练速度提升了10.7倍,这一显著的性能基准不仅展示了其技术优势,也为研究人员提供了参考标准。通过对比不同模型的训练步长,用户可以更好地理解LlamaRL在实际应用中的潜力和效果。
延伸问答
LlamaRL框架的主要特点是什么?
LlamaRL框架的主要特点包括完全异步设计、模块化定制、内存效率和高效的执行管理。
LlamaRL如何提高大型语言模型的训练效率?
LlamaRL通过异步执行和分布式直接内存访问(DDMA)显著提高了训练速度,405B参数模型的训练速度提高了10.7倍。
强化学习在大型语言模型训练中的作用是什么?
强化学习能够根据结构化反馈调整模型输出,提升模型性能,是微调大型语言模型的重要方法。
LlamaRL解决了哪些传统框架的问题?
LlamaRL解决了传统框架的效率低下、灵活性不足、内存限制和通信延迟等问题。
LlamaRL的设计如何支持大规模训练?
LlamaRL的设计支持在从几个到数千个GPU的集群上进行训练,采用单控制器设计简化协调。
LlamaRL在实际应用中的性能表现如何?
在实际应用中,LlamaRL在405B参数模型上将训练步长从635.8秒缩短至59.5秒,保持了稳定的性能。
