
Postgres开发者的向量索引权衡指南
内容提要
本文讨论了Postgres中的向量搜索及其索引设计,强调在不同工作负载下选择合适索引的重要性。介绍了HNSW、IVFFlat和DiskANN等算法,并分析了它们在内存、召回率和写入成本等方面的权衡。建议根据实际数据和查询模式进行基准测试,以优化检索质量和性能。
关键要点
-
Postgres中的向量搜索开始时简单,但随着工作负载的增加,索引设计变得复杂。
-
选择合适的索引需要考虑内存、召回率、写入成本和过滤器选择性等约束。
-
精确的k近邻搜索提供完美的召回率,但在数据量大时成本高,近似最近邻搜索(ANN)通过组织向量来降低查询延迟。
-
HNSW适合内存中的高召回率,IVFFlat适合写入敏感的工作负载,而DiskANN适合无法完全放入内存的大型数据集。
-
pgvector为Postgres添加了原生向量列类型,支持HNSW和IVFFlat索引。
-
pgvectorscale解决了索引超出内存的问题,通过StreamingDiskANN保持压缩表示在内存中以指导搜索。
-
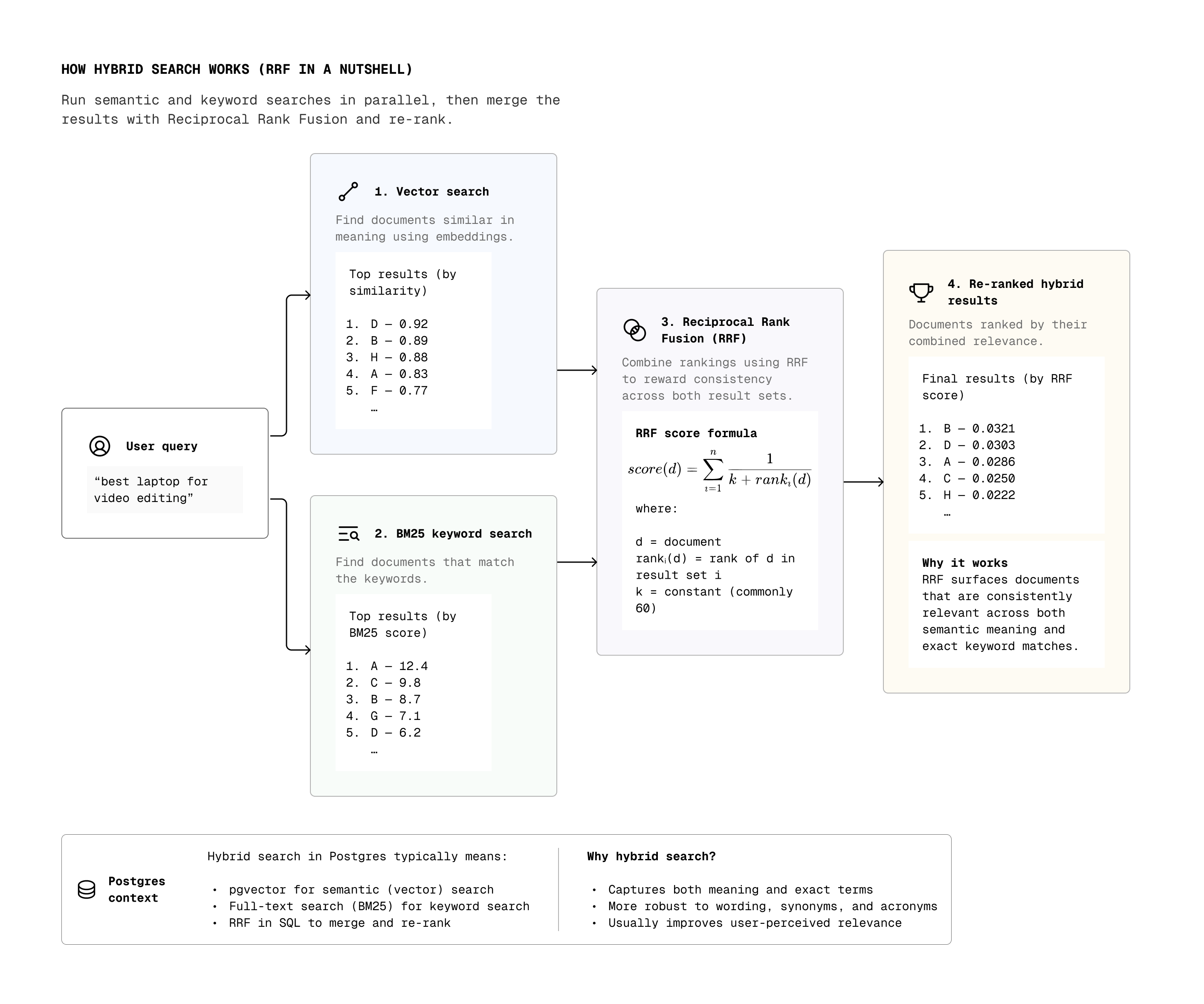
结合向量搜索和BM25关键词搜索可以提高检索质量,适用于许多应用场景。
-
选择索引时应根据实际数据和查询模式进行基准测试,以优化检索质量和性能。
延伸解读
向量索引选择的关键因素
在Postgres中选择向量索引时,开发者需要考虑多个因素,包括内存限制、召回率、写入频率和过滤器的选择性。不同的工作负载对这些因素的敏感度不同,因此在选择索引时,必须根据实际情况进行基准测试,以确保索引设计能够满足特定的性能需求。
近似最近邻搜索的权衡
近似最近邻(ANN)搜索通过牺牲部分召回率来提高查询速度和降低内存使用。对于大规模数据集,ANN索引可以显著减少查询延迟,但开发者需要仔细评估在特定应用中可接受的召回率损失,以平衡性能和准确性。
混合搜索的优势
结合向量搜索和BM25关键词搜索可以显著提高检索质量。向量搜索擅长捕捉语义相似性,而BM25则能有效处理精确匹配。通过在同一查询中融合这两种方法,开发者可以更好地满足用户的检索需求,尤其是在复杂的应用场景中。
