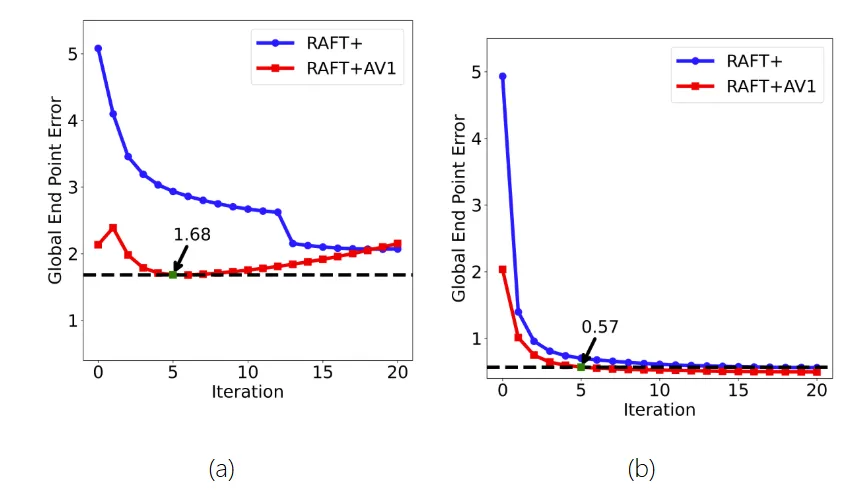
研究人员利用AV1视频编码中的运动矢量提升光流估计的效率与准确性。通过与真实数据对比,验证了其保真度,并发现将这些矢量作为深度学习算法RAFT的起点,可以将处理速度提高四倍,且精度影响最小。这为实时运动感知应用开辟了新可能。
本研究针对视频生成模型在遵循物理法则方面普遍存在的不足,提出了一种新的基准——PhyCoBench。该基准涵盖120个提示,涉及7类物理原理,评估生成视频的物理一致性。此外,我们还提出了PhyCoPredictor自动评估模型,实验结果表明其与人工评估的一致性最高,能够有效提升视频生成模型的优化方向。
本研究提出了一种基于残差的光流估计方法,有效解决了事件摄像头在高时间分辨率下运动估计的数据稀疏性问题,显著提高了准确性。
本研究改进了光流处理中的凸上采样方法,提出了解耦加权和上下文特征引入,开发了基于局部注意力的上采样器,实验结果表明这些改进提升了光流模型的精度。
本研究探讨了扩散模型在生成和视觉感知任务中的应用,提出了一种将深度估计、光流和分割统一为图像转换的高效训练技术。结果表明,该模型在数据和计算资源较少的情况下,性能与先进方法相当。
本研究提出了多种基于深度学习的显微成像重建方法,有效解决了各向异性分辨率问题。通过卷积神经网络、条件归一化流和扩散模型等技术,显著提升了3D重建质量,适用于生物医学研究和临床诊断。
本文介绍了一种基于深度学习的人体姿势估计算法,结合光流和时间序列信息,提升了多个数据集上的性能。研究提出了UniPose、AdaFuse和GateAttentionPose等方法,分别针对遮挡、三维姿态估计和计算效率进行了优化,均在相关数据集上取得了优异结果。
本文介绍了多种光流估计方法,如密集对应场、卷积网络和静态语义场景分割,旨在提高光流估计的准确性和鲁棒性。研究表明,采用新模型和数据集,尤其在复杂场景中,能够显著提升光流估计性能,特别是在小物体的识别和运动预测方面。
本文介绍了多种光流估计的新方法,如密集对应场方法、GMFlow框架和MeFlow,强调了自监督学习和注意力机制的应用。这些技术在多个数据集上表现优异,显著提高了光流估计的准确性和效率,同时降低了内存和时间成本。
本研究探讨了光流算法在人体动作识别中的应用,提出了一种基于深度学习的新方法来估计3D面部表情,强调了光流算法的精细调整对识别性能的提升。同时,研究介绍了面部情感微表情识别和面部交换框架FlowFace的创新,展示了其在多个数据库上的优越表现。
本研究解决了高分辨率图像下光流方法在内存消耗和计算效率方面的困难。提出了一种新颖的混合成本体积(HCV)策略,通过将4D成本体积分离为两个全局3D成本体积,显著减少内存使用,同时保留大量匹配信息。实验表明,基于HCV的光流网络在内存消耗和准确性方面均优于现有方法,具有良好的实用性和推广潜力。
本研究针对事件相机在快速运动或复杂光照条件下光流估计的需求,提出了SDformerFlow和STTFlowNet两种新的解决方案,利用时空窗口自注意力变换器和全脉冲神经网络架构。该研究首次应用脉冲变换器于光流估计,结果显示其在DSEC和MVSEC数据集上具有优越性能和显著减少的能耗。
本文介绍了一系列基于学习的运动信号分割方法,利用光流和事件相机技术实现独立运动目标的分割和运动参数估计。研究表明,新的视频实例分割方法通过融合多种线索,能够在复杂场景中实时跟踪实例,准确度高达90%。此外,提出的半监督框架在降低计算复杂度的同时,性能与完全监督方法相当,展示了在多目标跟踪中的有效性。
本文介绍了一系列运动分割和跟踪算法,包括基于光流和神经网络的方法。这些算法通过聚类像素、无监督学习和优化动态场景,提升了复杂背景下的运动分割性能。研究表明,这些新算法在多个数据集上表现优异,尤其在动态和非线性运动模式的场景中。
本文介绍了多种光流估计方法,包括基于全局优化的光流估计、神经网络优化、无监督学习的DDFlow和快速光流预测的FastFlowNet。这些方法在准确性、效率和实时性方面有显著提升,适用于复杂环境中的自主导航和视觉任务。
本文介绍了一种基于事件相机的深度学习方法,结合卷积循环神经网络和可微分方向事件过滤模块,旨在恢复运动模糊图像。研究提出了光流估计算法,并通过实验验证其优越性。同时,利用动态视觉传感器进行视频帧插值,结合事件引导光流细化策略,获得更真实的中间帧结果。
本文研究了基于事件相机的光流无监督学习算法,提出了自监督学习框架和新的数据集,以提高光流估计的准确性和效率。实验结果表明,这些方法在多个数据集上表现优越,适用于高频推理和低延迟应用。
本文介绍了一种自我监督的场景流估计技术,利用卷积神经网络和光流代价体积,提高了三维运动和深度估计的精度。该方法在多个数据集上表现优异,超越了传统监督学习,适用于动态环境中的物体移动估计。
本文介绍了一种运动分割算法,利用光流方向和概率模型聚类相似运动的像素,有效解决深度相关分割问题。该系统在复杂背景下表现优异,特别是在不同深度物体的运动分割方面。研究还提出了自监督学习框架和深度估计方法,结合光流信息提升了运动预测的准确性和效率。
本文讨论了铁路障碍物检测的重要性,提出了一种利用浅层网络进行铁路图像分割的方法,并在人工增强障碍物的数据集上进行了评估,结果显示该方法优于其他学习基准。此外,介绍了基于光流的移动物体检测框架和无标注图像分割技术,强调了这些技术在复杂场景中的应用和优势。
完成下面两步后,将自动完成登录并继续当前操作。