

在Amazon EKS上使用vLLM深度学习容器部署大型语言模型(LLMs)
💡
原文英文,约3700词,阅读约需14分钟。
📝
内容提要
组织在大规模部署大型语言模型(LLMs)时面临优化GPU资源、管理网络基础设施和高效访问模型权重等挑战。vLLM是一个开源库,旨在简化LLM推理和服务的部署,AWS深度学习容器(DLCs)提供优化环境以支持高性能推理。结合AWS服务,用户可以高效部署LLMs,降低复杂性并提升性能。
🎯
关键要点
- 组织在大规模部署大型语言模型(LLMs)时面临优化GPU资源、管理网络基础设施和高效访问模型权重等挑战。
- vLLM是一个开源库,旨在简化LLM推理和服务的部署。
- AWS深度学习容器(DLCs)提供优化环境以支持高性能推理,用户可以高效部署LLMs,降低复杂性并提升性能。
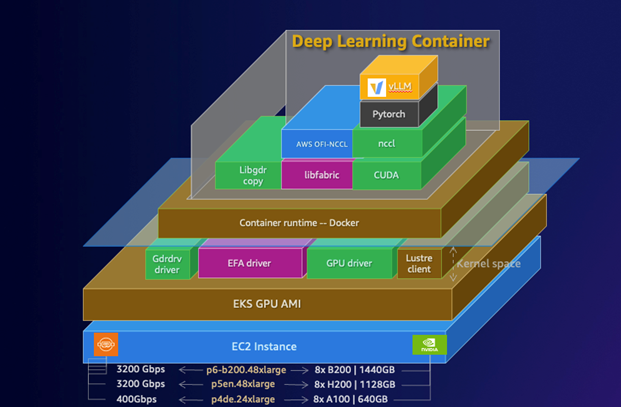
- AWS DLCs为自管理的机器学习客户提供优化的Docker环境,支持在Amazon EC2、EKS和ECS上训练和部署生成性AI模型。
- AWS DLCs提供预配置的环境,简化部署过程,降低AI/ML基础设施的总拥有成本(TCO)。
- 通过结合Amazon EKS、GPU支持的EC2实例和FSx for Lustre存储,构建高性能的LLM推理系统。
- 使用Elastic Fabric Adapter(EFA)提高多节点推理工作负载的性能,降低延迟和提高吞吐量。
- FSx for Lustre提供高吞吐量、低延迟的数据访问,适合存储大型模型权重。
- AWS Load Balancer Controller用于管理Kubernetes服务的外部访问,支持路径路由和SSL/TLS终止。
- 部署完成后,可以通过API测试vLLM服务器,验证其功能和性能。
- 使用AWS DLCs和Amazon EKS的组合,可以实现LLM推理的最佳性能,同时保持Kubernetes的灵活性和可扩展性。
➡️
