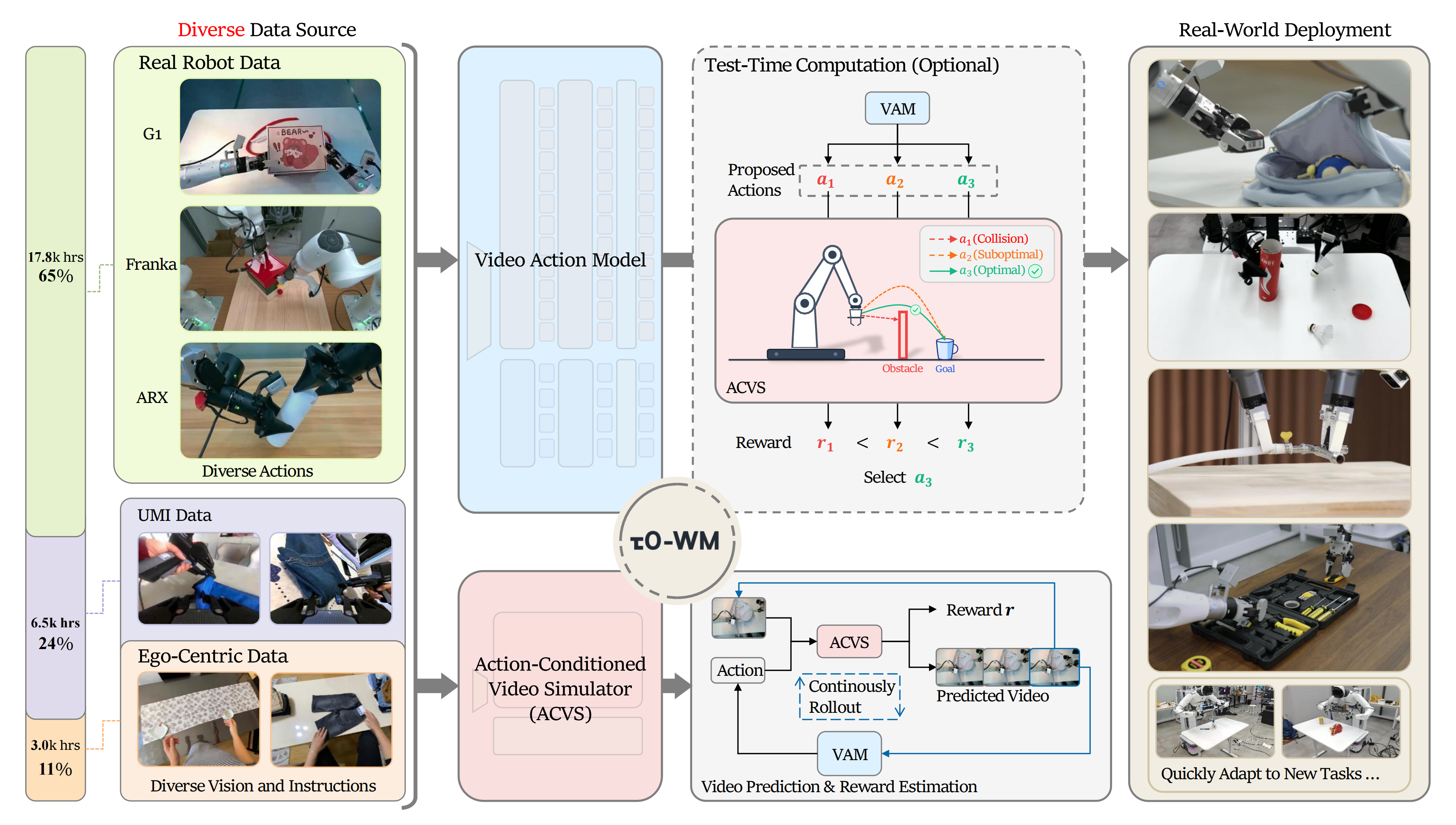
研究者提出了一种名为τ0-World Model(τ0-WM)的统一视频-动作世界模型,旨在提升机器人操作的预测能力。该模型结合视频预测、动作生成和任务评估,利用27,300小时的多样化数据进行训练。τ0-WM通过共享的预测网络,提供视频动作模型和动作条件视频模拟器两个接口,优化机器人在执行前的决策过程。
本文探讨了一种双执行体强化学习框架,结合人类反馈优化视觉-语言-动作(VLA)模型。通过“对话与微调”机制,机器人在长时域操作中实现高效学习,成功率达到100%。该方法在多任务设置中展现出良好的样本效率和训练稳定性,适用于复杂的机器人操作任务。
Runway发布了首个通用世界模型GWM-1及其变体,包括GWM Worlds、GWM Avatars和GWM Robotics,基于Gen-4.5构建。GWM Worlds支持实时环境模拟,GWM Avatars用于人类对话模拟,GWM Robotics提升机器人操作的训练效率和安全性。同时,Gen-4.5还增强了音频生成与编辑功能。
本文介绍了VITAL策略学习框架,通过将操作任务分为到达和局部交互两个阶段,结合视觉和触觉感知,提高机器人在精细操作中的成功率和泛化能力。VITAL利用视觉-语言模型进行目标定位,并通过触觉反馈实现高精度操作,克服了模仿学习和强化学习的局限性。
Meta推出V-JEPA 2,这是一种新型视频世界模型,旨在提升机器对物理环境的理解和预测能力。该模型经过两阶段训练,首先自监督预训练超过一百万小时的视频,然后在62小时的机器人数据上微调。V-JEPA 2在机器人操作任务中表现优异,成功率达65%至80%。
本研究提出了知识捕捉、适应与组合(KCAC)框架,旨在解决机器人操作中强化学习的样本低效和可解释性不足的问题。该框架在复杂环境中实现了40%的训练时间缩短和10%的任务成功率提升,为强化学习中的课程设计应用提供了重要见解。
本研究提出了ManipBench基准,用于评估视觉-语言模型在低级机器人操作中的有效性。结果表明,不同模型在任务表现上存在显著差异,并且与真实操作任务相关,显示出模型与人类理解之间的明显差距。
本研究提出了一种新颖的视觉-语言-行动模型FSD,旨在解决机器人操作中的泛化问题。FSD通过空间关系推理生成中间表示,显著提高了零-shot机器人操作任务的成功率。
本文讨论了π0.5模型在机器人操作中的进展,强调其在未知环境中执行复杂任务的泛化能力。模型通过结合多种数据源,采用分层架构进行预训练和微调,展现出高效的推理能力和多模态数据的协同训练。
本研究提出了Bi-LAT,一个结合双边控制与自然语言处理的模仿学习框架,旨在实现机器人操作中的精确力调节。该方法通过多模态变换器模型编码人类指令,有效区分真实任务中的微妙力需求。
本研究提出了一种不确定性感知的政策优化框架,旨在解决模型基强化学习中的策略学习偏差问题。通过主动收集不确定样本以提高模型准确性,实验结果表明该方法在机器人操作和Atari游戏中优于现有技术。
论文《ET-SEED: 高效轨迹级SE(3)等变扩散策略》提出了一种新方法,能够在少量示范数据下学习复杂操作技能,并在不同物体姿态和环境中实现良好泛化。该方法在多个机器人操作任务中表现优异,显著提高了数据利用效率和泛化能力。
本文提出了一种低成本的数据生成管道,结合物理模拟和人类示范,有效生成用于机器人操作任务的数据集。通过轨迹优化技术,处理虚拟现实中的示范数据,适应不同机器人形态,实现数据重用。实验表明,训练的策略能在多种机器人形态下成功执行复杂任务。
本研究提出了一种新颖的语义方向概念,解决了视觉语言模型在物体方向理解上的不足。通过构建OrienText300K数据集,提升了机器人操作的精度,具有广泛应用潜力。
本研究提出了一种名为S$^2$-扩散的策略,旨在解决机器人操作中技能学习仅限于特定实例的问题。该方法结合语义模块与空间表示,实现技能从实例级到类别级的推广,实验表明其在类别无关因素变化时仍能保持性能,并有效转移技能至其他实例。
本研究提出了一种3D基础视觉语言框架,解决了多模态语言模型在机器人操作中的3D场景定位问题。通过将2D图像映射到点云并引入小型语言模型,显著提升了3D场景理解能力,实验显示任务成功率达到96.0%。
本研究提出了CordViP框架,旨在解决机器人操作中的灵巧性问题。该方法结合物体的6D姿态估计和机器人本体感知,在四个现实任务中实现了90%的成功率,展现了优越的泛化能力和鲁棒性。
AIxiv专栏促进学术交流,报道超过2000篇内容。北大与智元机器人团队提出OmniManip架构,解决视觉语言模型在机器人操作中的挑战,实现高效低层次动作。该系统通过双闭环设计显著提升操作性能,展现强大的零样本泛化能力。
本文探讨了视觉-语言-动作(VLA)模型在机器人操作中的应用与挑战,提出了GRAPE方法,通过偏好对齐提升机器人策略的泛化能力。GRAPE利用视觉语言模型分解任务,优化轨迹以适应不同操控目标,旨在降低强化学习成本并提高灵活性。
本研究提出ET-SEED模型,旨在解决模仿学习中对示例的依赖问题,从而显著提升机器人操作任务的训练和数据效率。
完成下面两步后,将自动完成登录并继续当前操作。