

💡
原文中文,约2600字,阅读约需7分钟。
📝
内容提要
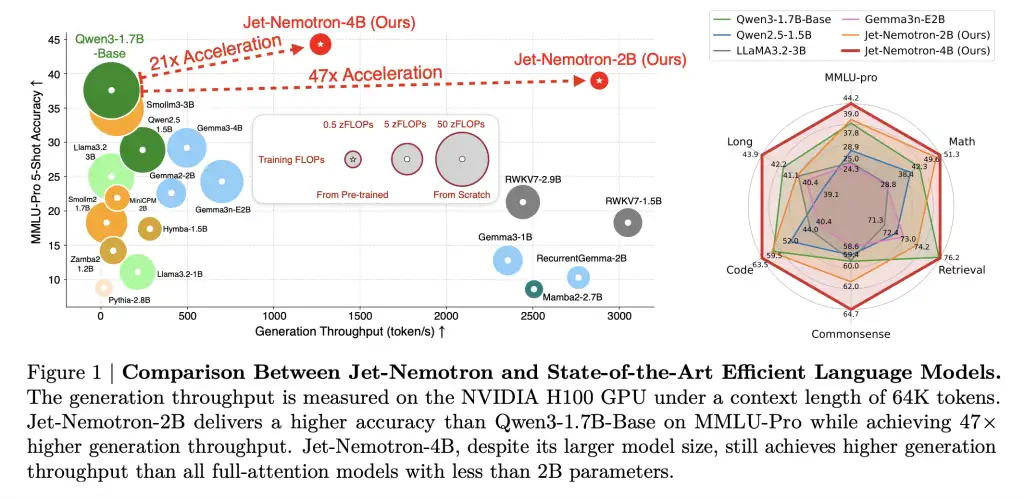
NVIDIA发布了Jet-Nemotron模型系列,利用后神经架构搜索技术显著提升了大语言模型的生成吞吐量,达到53.6倍,同时保持或超越准确率。这一创新降低了计算和内存成本,使得边缘设备的大规模部署成为可能,提升了AI应用的经济性和效率。
🎯
关键要点
- NVIDIA发布Jet-Nemotron模型系列,生成吞吐量提升53.6倍,准确率持平或超越。
- 采用后神经架构搜索技术对现有预训练模型进行改造,降低计算和内存成本。
- 现代LLM的O(n²)自注意力机制导致高昂的计算和内存成本,限制了大规模部署。
- PostNAS技术通过冻结知识和精准替换,优化了模型的训练和性能。
- JetBlock模块替代全注意力机制,提升了硬件效率和准确性。
- Jet-Nemotron模型在多个基准测试中表现优异,吞吐量和内存占用显著降低。
- 企业可实现更高的投资回报率,推理成本降低98%。
- 边缘设备上无需重新训练即可使用Jet-Nemotron,适应性强。
- PostNAS降低了LLM架构创新的成本,促进了更快的迭代和创新。
- Jet-Nemotron的开源将推动AI生态系统的效率提升。
➡️
