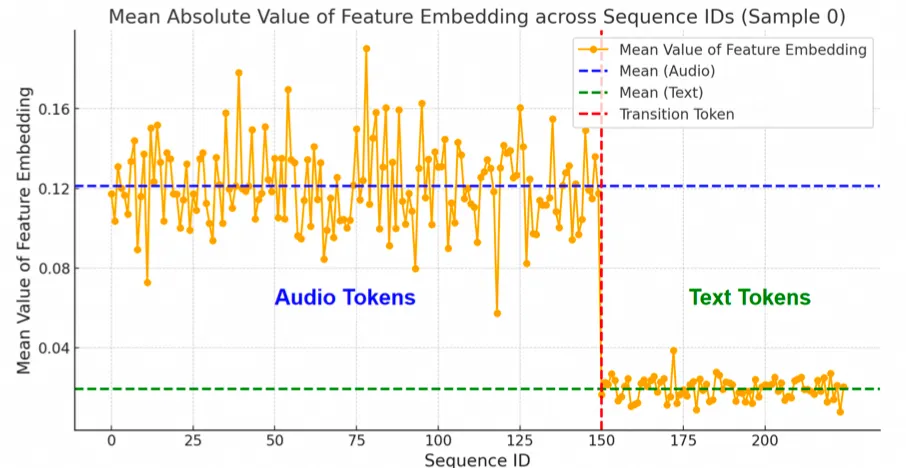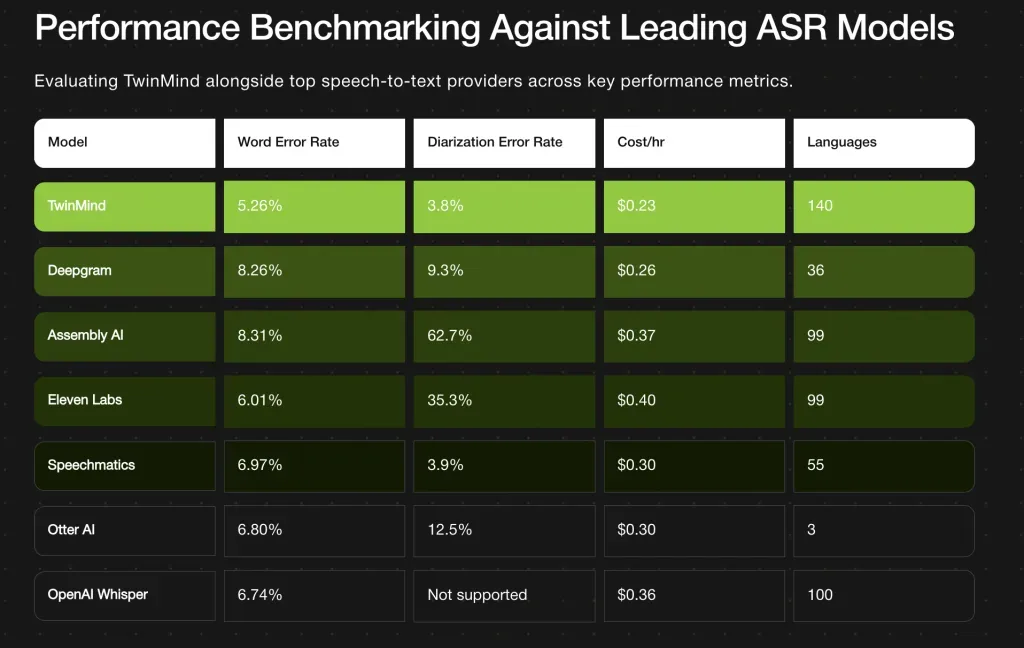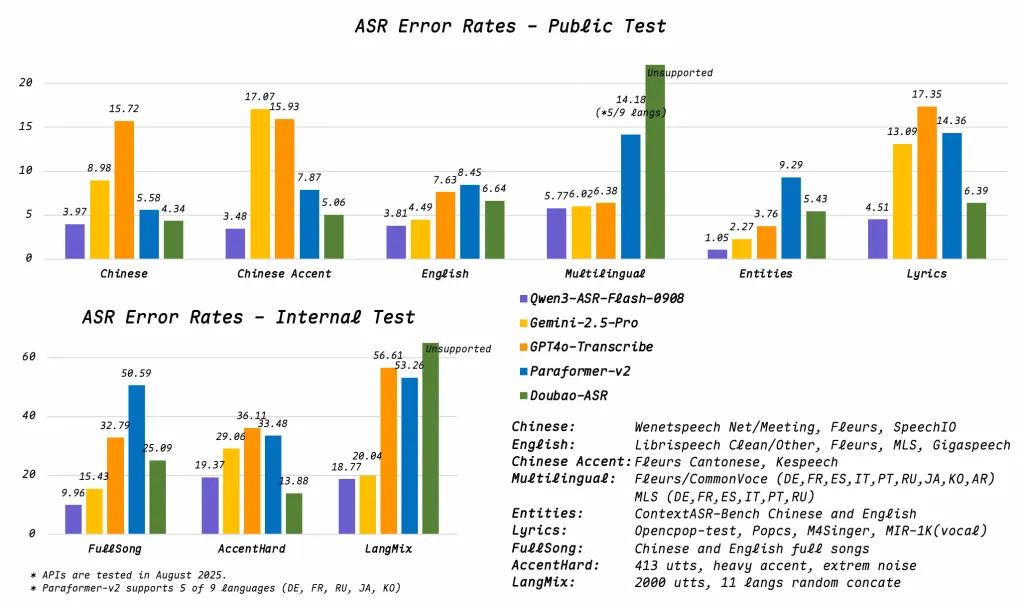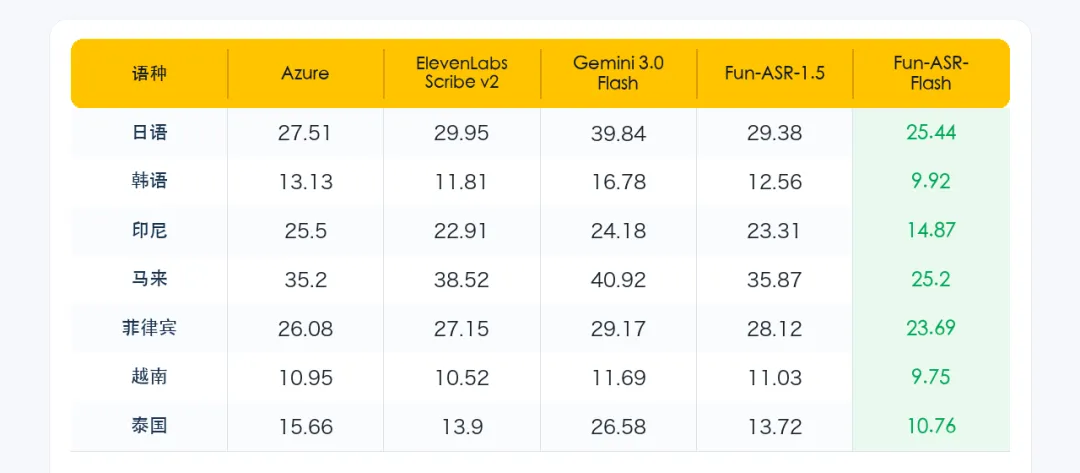



如何训练AI语音开发模型?从数据准备到三层优化的实操路径
实时互动网
·

哪些AI语音开发平台收费低?了解最省钱的选型组合
实时互动网
·
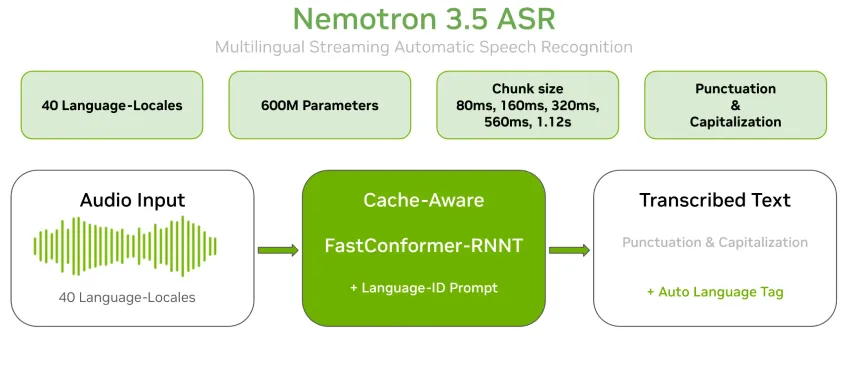

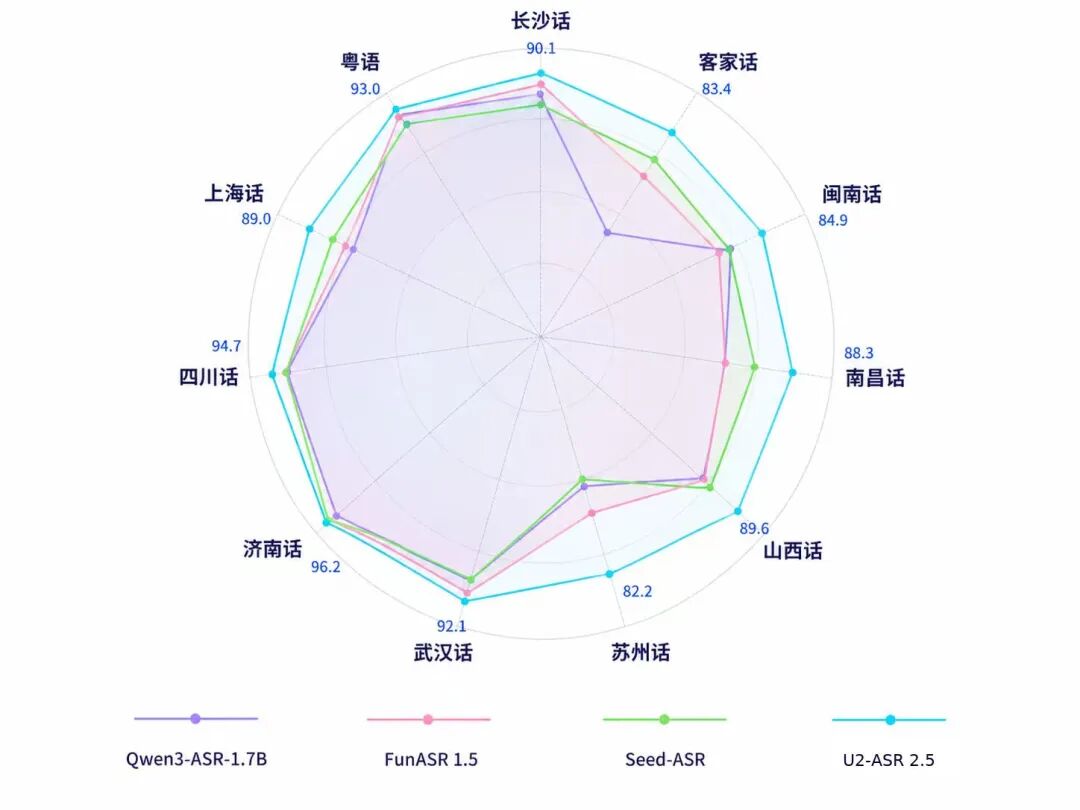
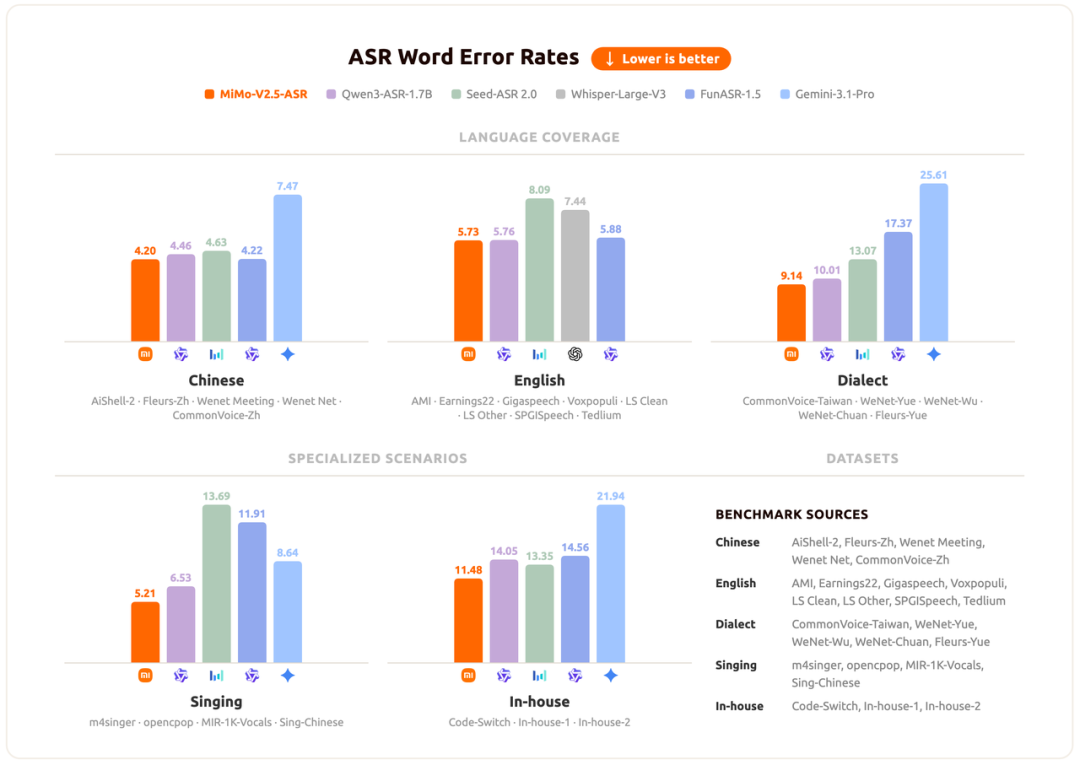
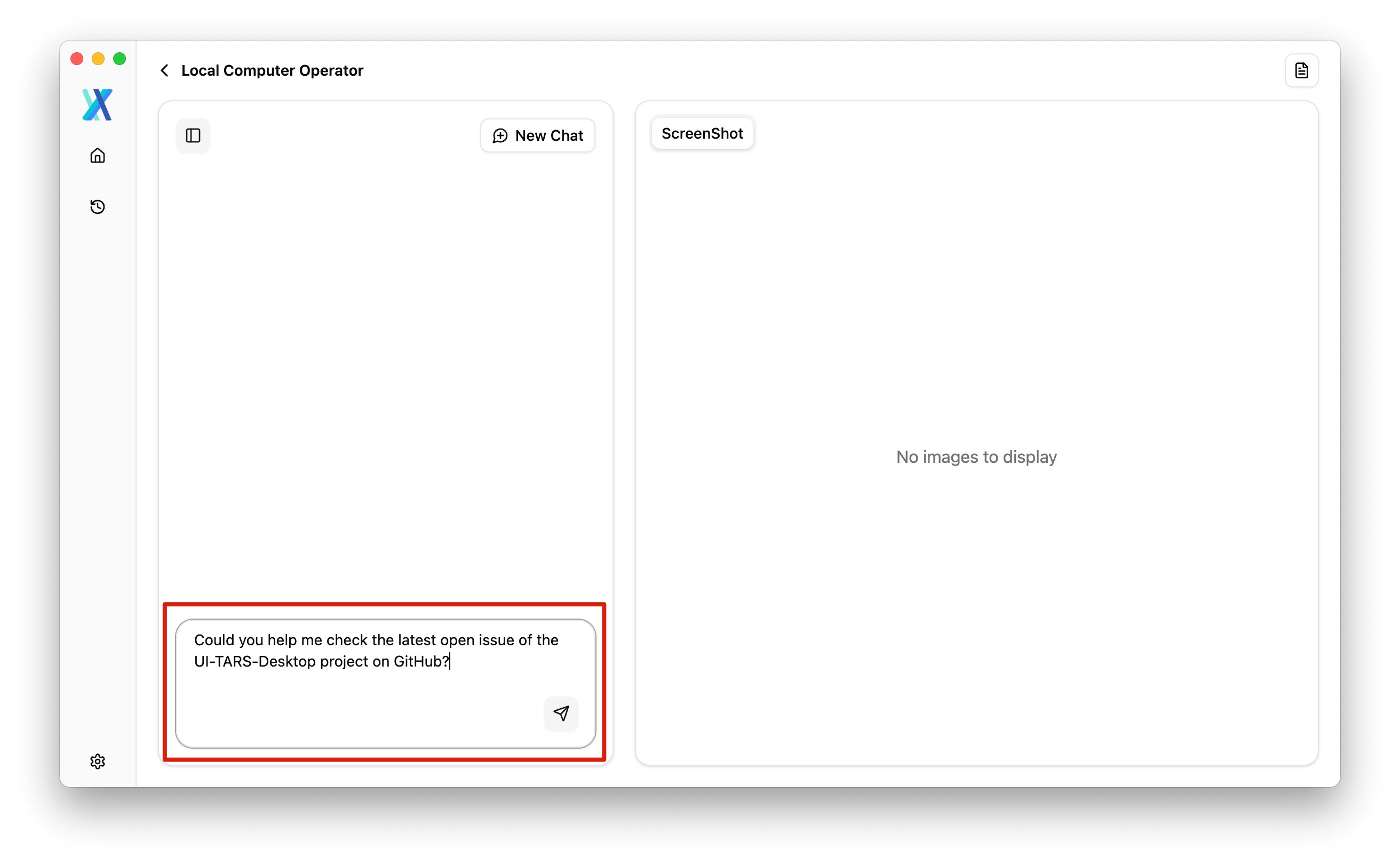
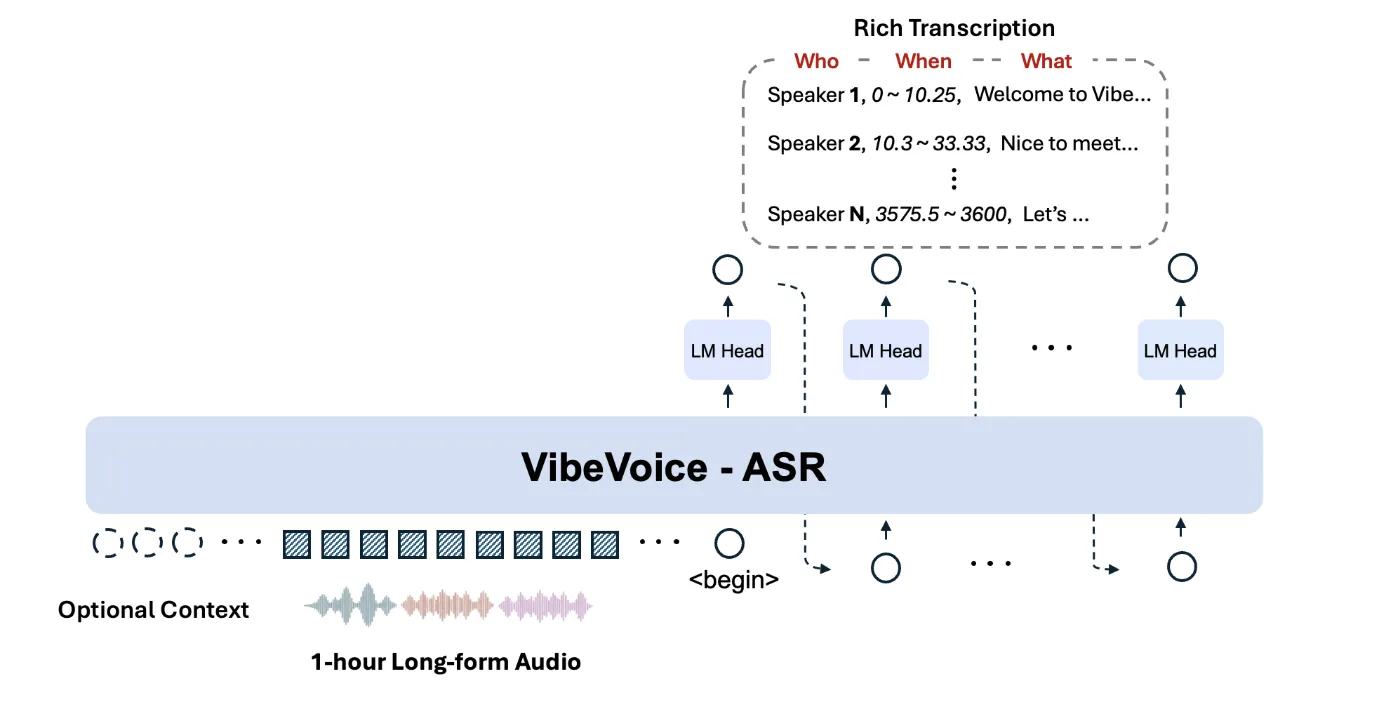

低延迟实时语音识别(ASR)模型部署实践与选型
亚马逊AWS官方博客
·
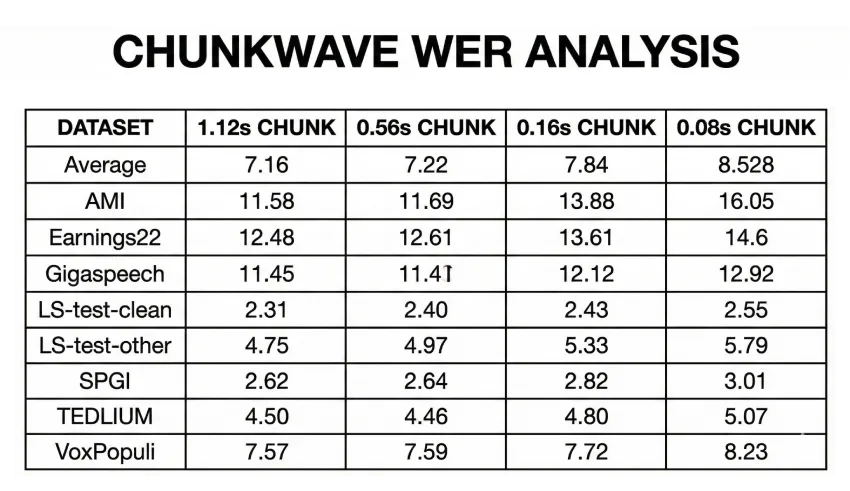

GLM ASR试用
年华转瞬
·